

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Redis
- nosql
- mapping
- CodeCommit
- codebuild
- orm
- aws
- Docker
- 자격증
- backenddeveloper
- QueryDSL
- goorm x kakao
- codedeploy
- 티스토리챌린지
- 오블완
- rds
- sqs
- goorm
- MSA
- 개발자
- CICD
- 스터디
- DynamoDB
- s3
- spring
- jpa
- serverless
- data
- bootcamp
- Spring Boot
- Today
- Total
gony-dev 님의 블로그
Section 31. AWS 기타 서비스 본문
AWS SES(Simple Email Service)
말 그대로 간단히 이메일을 보내는 서비스이다.
- SMTP 인터페이스나 AWS SDK로 사람들에게 메일을 보낸다.
- 메일을 받기 위해서는 S3나 SNS, Lambda와 통합할 수 있다.
Amazon OpenSearch Service
해당 서비스는 Amazon ElasticSearch의 후속작이라고 생각하면 된다.
DynamoDB에서는 PK나 인덱스를 통해서만 데이터를 쿼리할 수 있었다.
하지만 OpenSearch 사용 시 일부만 매칭이 되어도 모든 필드를 검색할 수 있다.
OpenSearch는 두 가지 모드로 클러스터를 프로비저닝할 수 있다.
- Managed Cluster
- 물리적 인스턴스가 프로비저닝
- Serverless Cluster
- 서버리스 상태로 프로비저닝
Cognito나 IAM, KMS 암호화 등을 통해 보안을 생성할 수 있으며, OpenSearch 대시보드를 통해 시각화할 수 있다!
1. OpenSearch를 이용한 DynomoDB

2. OpenSearch를 이용한 CloudWatch Logs

3. OpenSearch를 이용한 Kinesis Data Streams & Kinesis Data Firehose

Amazon Athena
Athena는 AmazonS3 버킷에 저장된 데이터의 분석을 도와주는 서버리스 쿼리 서비스이다.
Athena의 목적은 사용자가 S3 버킷에 데이터를 로드하거나 여러분이 S3 버킷에 데이터를 로드했을 때 Athena 서비스를 사용해 데이터를 쿼리하여 분석하는 것이다.
지원하는 파일 포맷 형식은 CSV, JSON, ORC 등으로 다양하며 요금 정책도 단순하다.
서비스 전체가 서버리스 이기에 따로 데이터베이스를 프로비저닝할 필요가 없다!!
Amazon Athena는 주로 임의 쿼리 실행, 비즈니스 인텔리전스, 분석, 보고 등에 사용한다. 이 외에도 VPC 흐름 로그나 로드 밸런서 로그, CloudTrail 추적 등을 분석할 수 있다.
Athena 성능 향상
성능을 향상시키는 방안에는 여러 가지가 있다.
1. 비용 절약을 위한 컬럼형 데이터
- 데이터 스캔이 적게 일어나도록 하는 것이 목적이다.
- 적합한 데이터 포맷은 Apache Parquet과 ORC로 이 포맷을 사용하면 성능을 개선할 수 있다.
- 둘 중 ORC 포맷은 변환하려면 다른 서비스를 사용해야한다.
바로 Glue 서비스로, Glue를 사용하면 데이터를 손쉽게 ETL 작업으로 변환할 수 있다.
2. 데이터를 압축
- 스캔하는 데이터의 양을 줄이기 위해 데이터를 압축하여 반환 용량의 크기를 줄여야 한다.
- 데이터를 압축하는 데 사용할 수 있는 메커니즘은 bzip2, gzip, lz4, zlip 등이 있다.
3. 분할 데이터셋
- 데이터 세트를 분할하려면 S3 버킷에서 전체 경로 뒤에 '/'를 붙이고, 각 슬래시에 분할할 열 이름과 값을 넣으면 된다.
- S3에서 데이터를 분할하여 구성하면, 데이터를 쿼리할 때 S3의 어느 경로에 데이터를 스캔해야 하는지 알 수 있다!
4. 큰 파일을 사용
- 큰 파일을 사용하여 오버헤드를 최소화한다.
- Athena는 S3에 용량이 작은 파일이 여러 개 있을 때보다 128MB 이상의 큰 파일이 있을 때 성능이 더 좋다.
사이즈가 큰 파일이 스캔 및 반환하기 쉽기 때문이다.
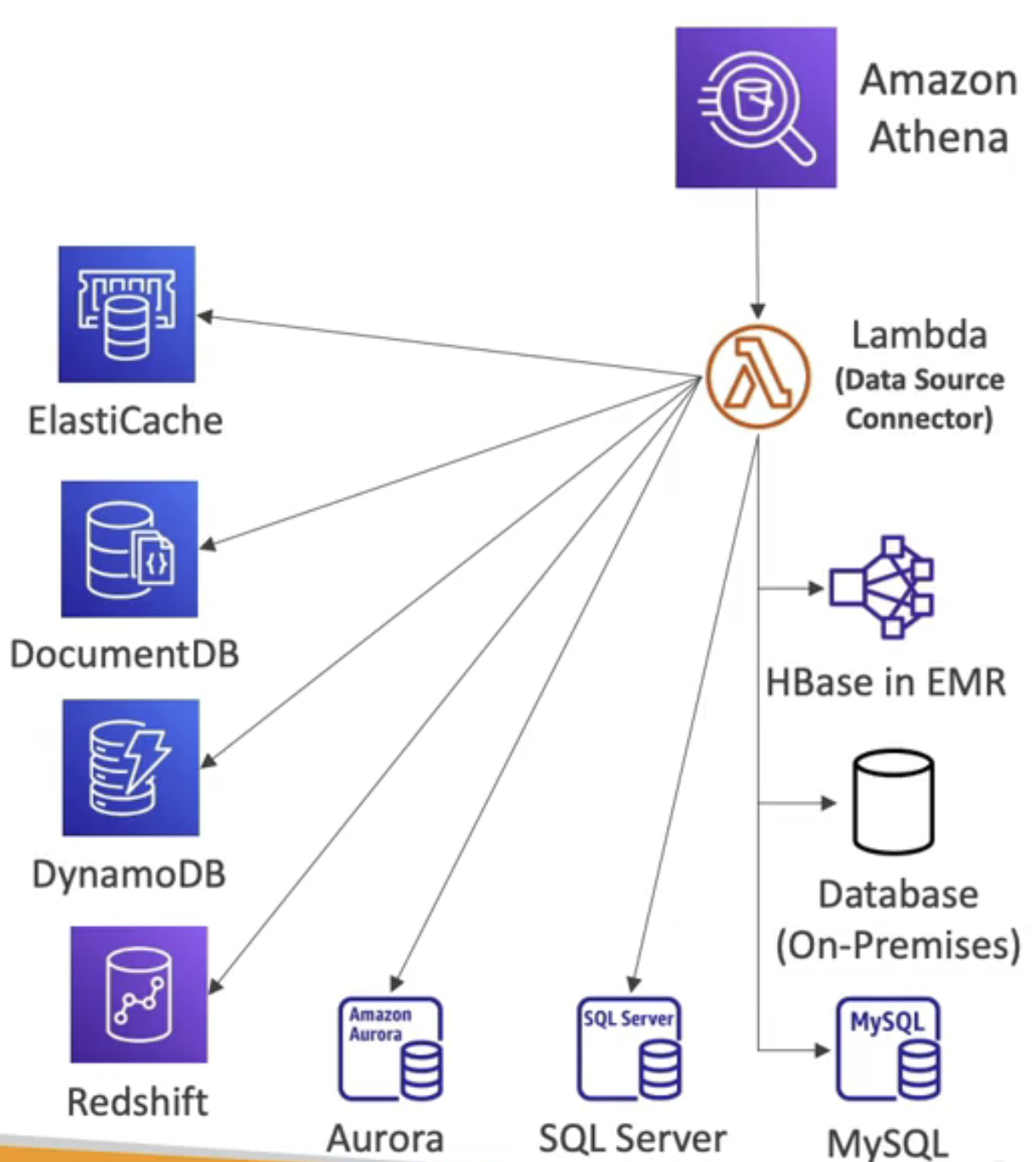
Athena - Federated Query(연합 쿼리)
- Athena는 S3에 있는 데이터뿐만 아니라 모든 곳에서 데이터를 쿼리할 수 있다.
- 연합 쿼리 기능은 당신에게 SQL 쿼리가 관계형 또는 비관계형 DB에 있는 데이터와 AWS 또는 온프레미스에 있는 객체 및 사용자 정의 데이터 소스를 가져올 수 있다. 이것은 "데이터 소스 커넥터"를 사용하는 것이다.
- "데이터 소스 커넥터"는 람다 함수를 사용해 람다 함수가 다른 서비스에 연합 쿼리를 실행하도록 만든다.
Amazon MSK
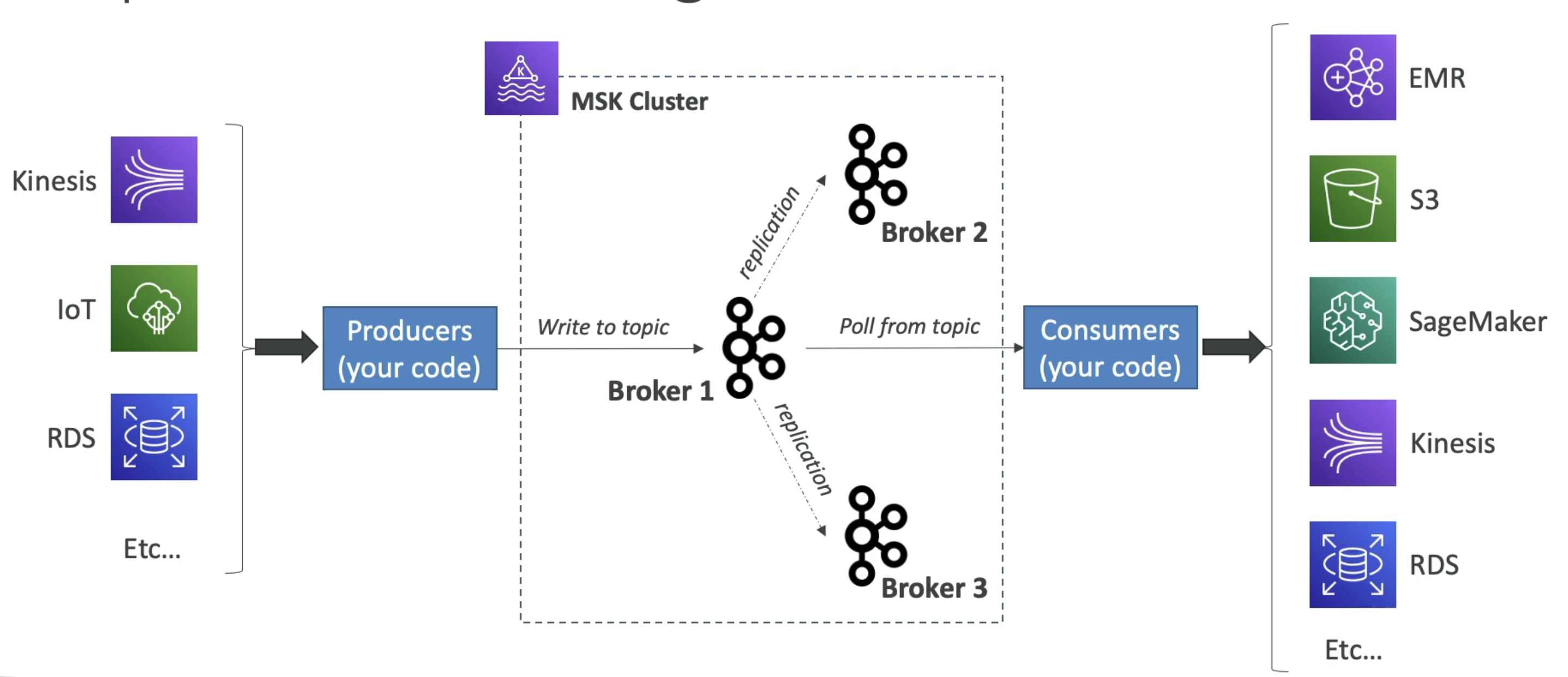
- MSK를 사용하면 AWS에서 완전관리형 Kafka 클러스터를 구성할 수 있고,
클러스터를 그 자리에서 생성하고 업데이트하고 삭제할 수 있다. - MSK는 클러스터에 Kafka 브로커 노드와 ZooKeeper 브로커 노드를 생성하여 관리하고,
해당 클러스터를 VPC와 여러 AZ에 배포할 수 있다.(최대 3곳까지 가능) - MSK는 서버리스로 용량을 관리하지 않고 Apache Kafka를 사용할 수 있다.
Apache Kafka
Kafka는 데이터를 스트리밍하는 데 사용한다.
Kinesis Data Streams vs. Amazon MSK
1. Kinesis Data Streams
- 메시지 크기가 1MB로 제한되어 있다.
- 샤드라는 개념을 사용
- 샤드 분할과 샤드 병합으로 규모를 조정한다.
- 전송 중 암호화를 사용
2. Amazon MSK
- 1MB가 기본값이며, 그 이상도 사용할 수 있다.
- 분할을 위해 Kafka 토픽을 사용한다.
- 토픽에 파티션만 추가할 수 있다.
- 평문이나 전송 중 암호화를 사용한다.
Amazon MSK Consumers
MSK에 데이터를 추가하려면 Kafka 프로듀서를 만들어야 한다. MSK에서 데이터를 가져오는 건 여러 가지로 할 수 있다.
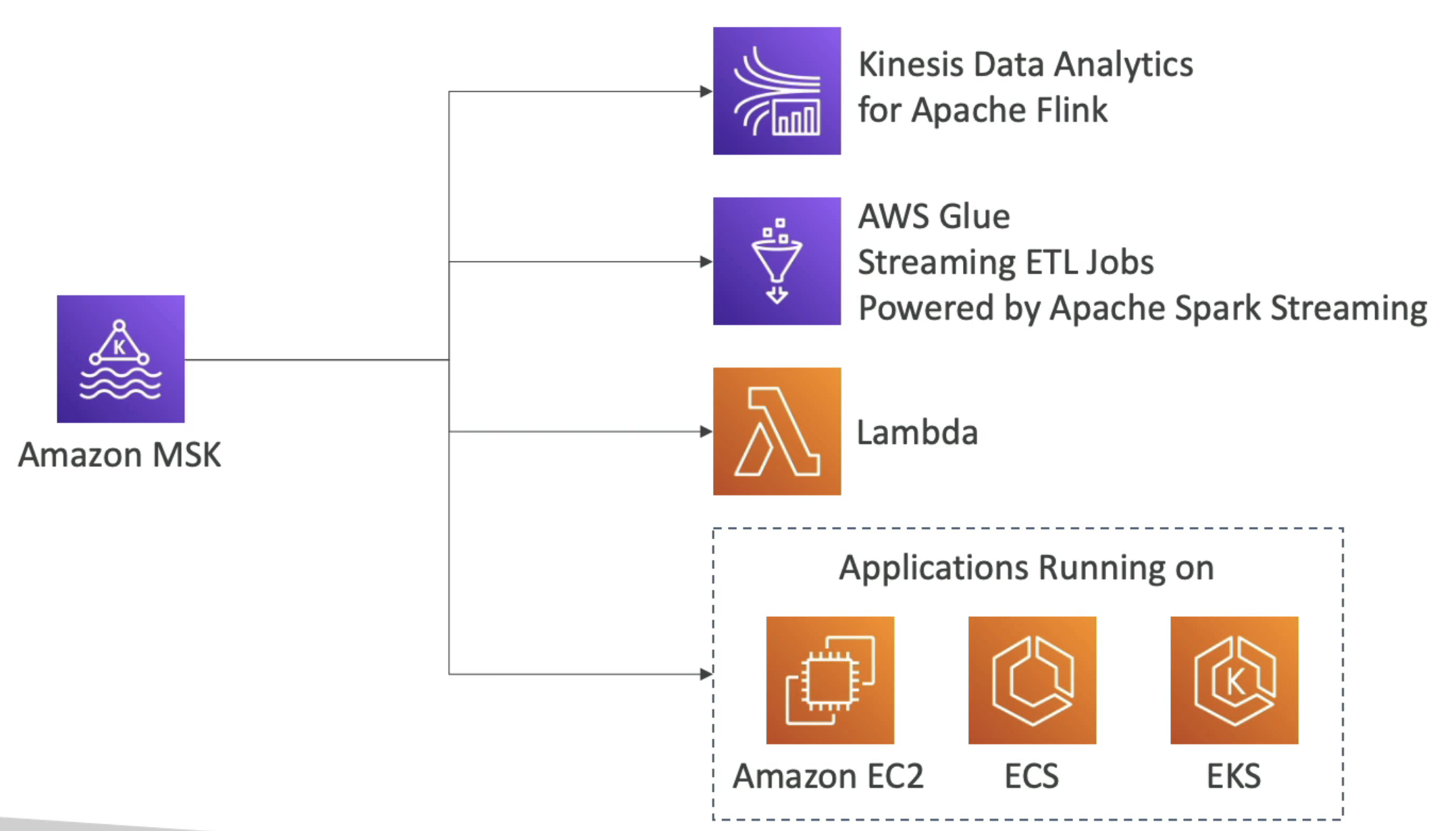
1. Apache Flink용 Kinesis Data Analytics
2. AWS Glue
3. Lambda gkatn
4. Kafka 컨슈머를 직접 작성
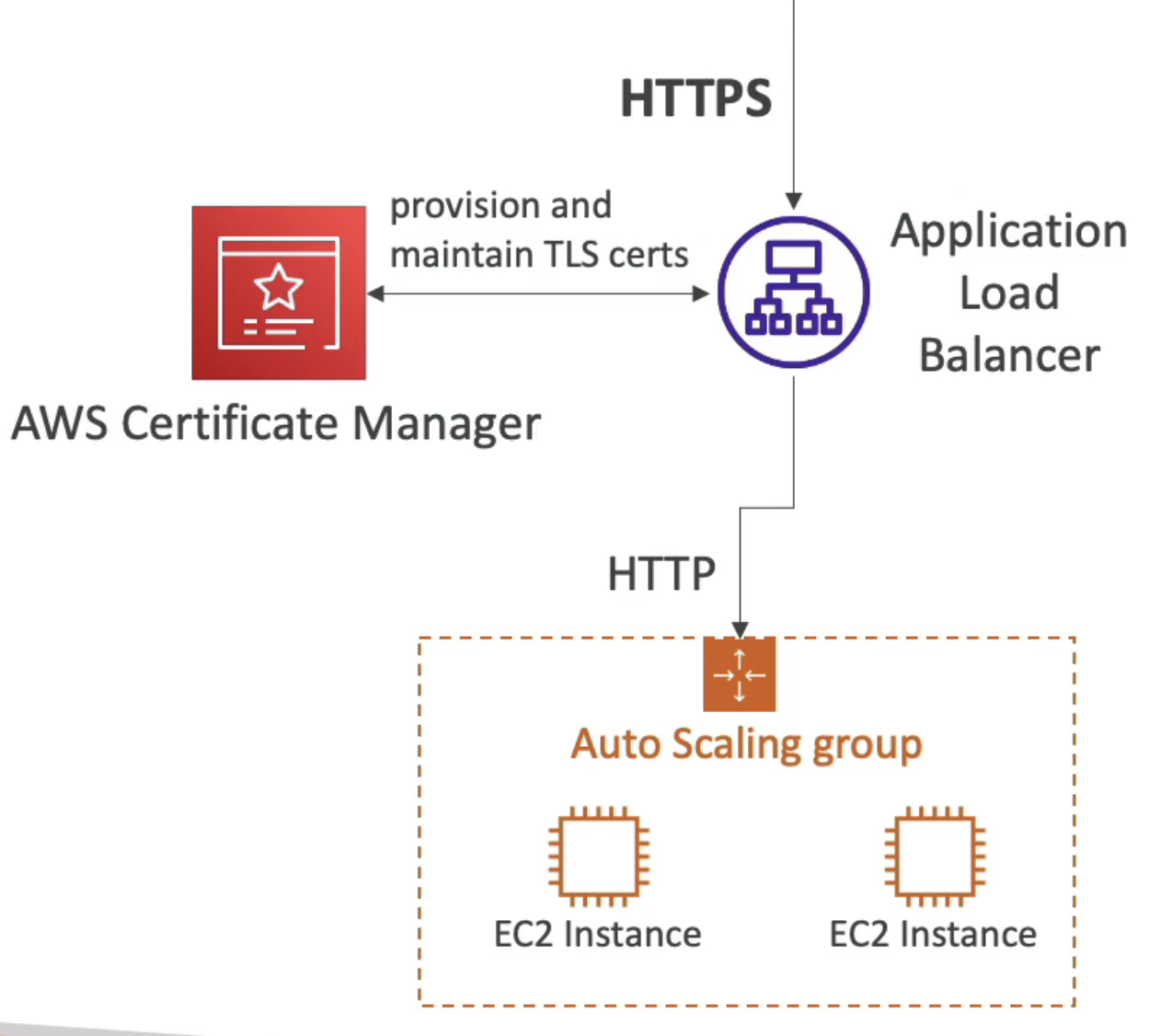
AWS Certificate Manager(ACM)
ACM을 사용하면 쉽게 프로비저닝, 관리, 배포를 진행할 수 있다.
HTTPS를 통해 전송 중 암호화를 제공한다.
ACM은 공용 및 사설 TLS 인증서를 지원하며 공용은 무료이다.
또한 TLS 인증서 자동 갱신 기능이 있어 유용하다.
AWS Private Certificate Authority(CA)
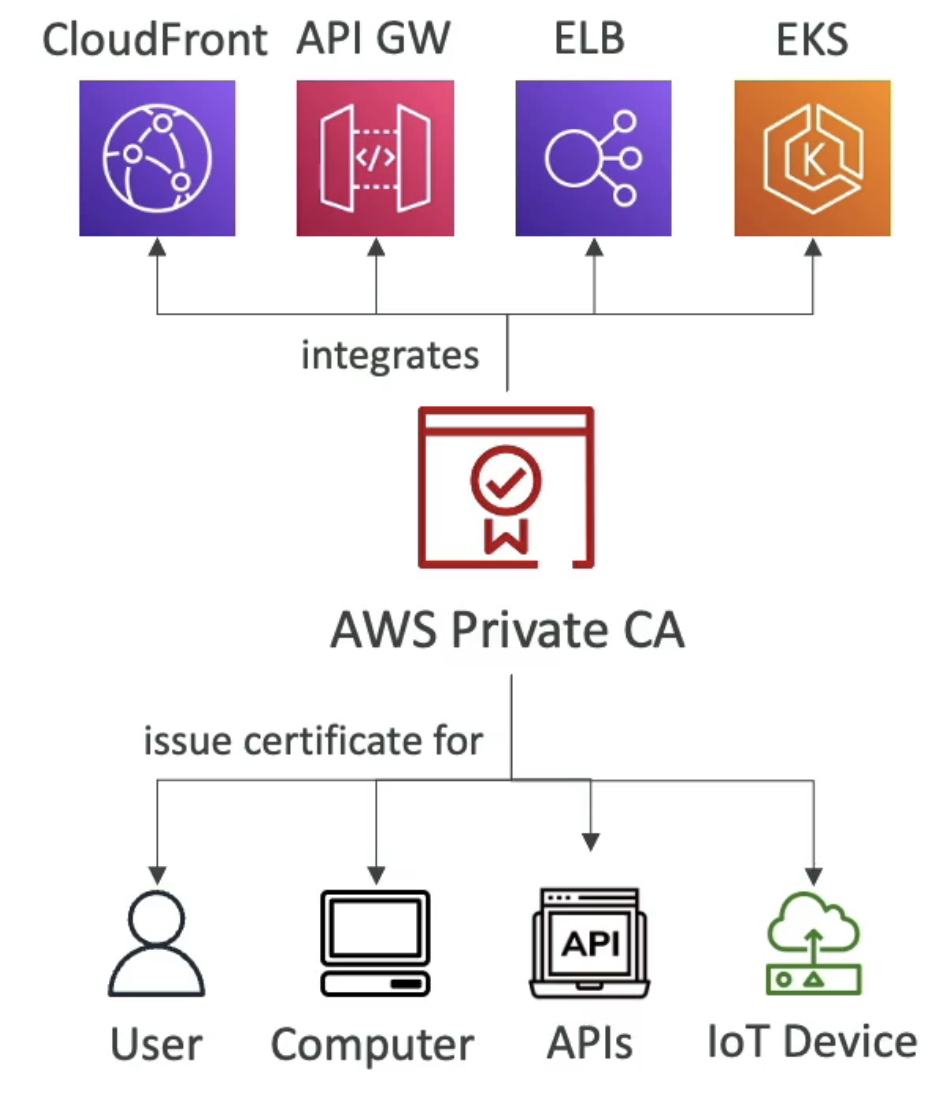
사설 인증서를 발급하기 위해서는 CA가 필요하다.
이는 관리형 서비스로 루트 인증 기관이나 하위 인증 기관을 생성할 수 있다.(하위 인증 기관은 루트에 종속된 기관을 뜻함)
- CA를 사용하여 엔드 엔티티 x.509 인증서를 발급하여 배포할 수 있다.
즉 어플리케이션에서 사용할 수 있는 인증서임을 나타낸다. - 이 인증서는 AWS 조직 내에 있는 어플리케이션에서만 신뢰할 수 있다.
사설 기관을 신뢰하도록 설정되어 있는 경우에 한해서 말이다. 그렇기에 공용 인터넷에 배포할 수 없다. - 사용 중인 AWS 서비스에서 ALB와 같은 ACM을 지원하고 있다면 발급한 사설 인증서를 로드하여 사용할 수 있다.
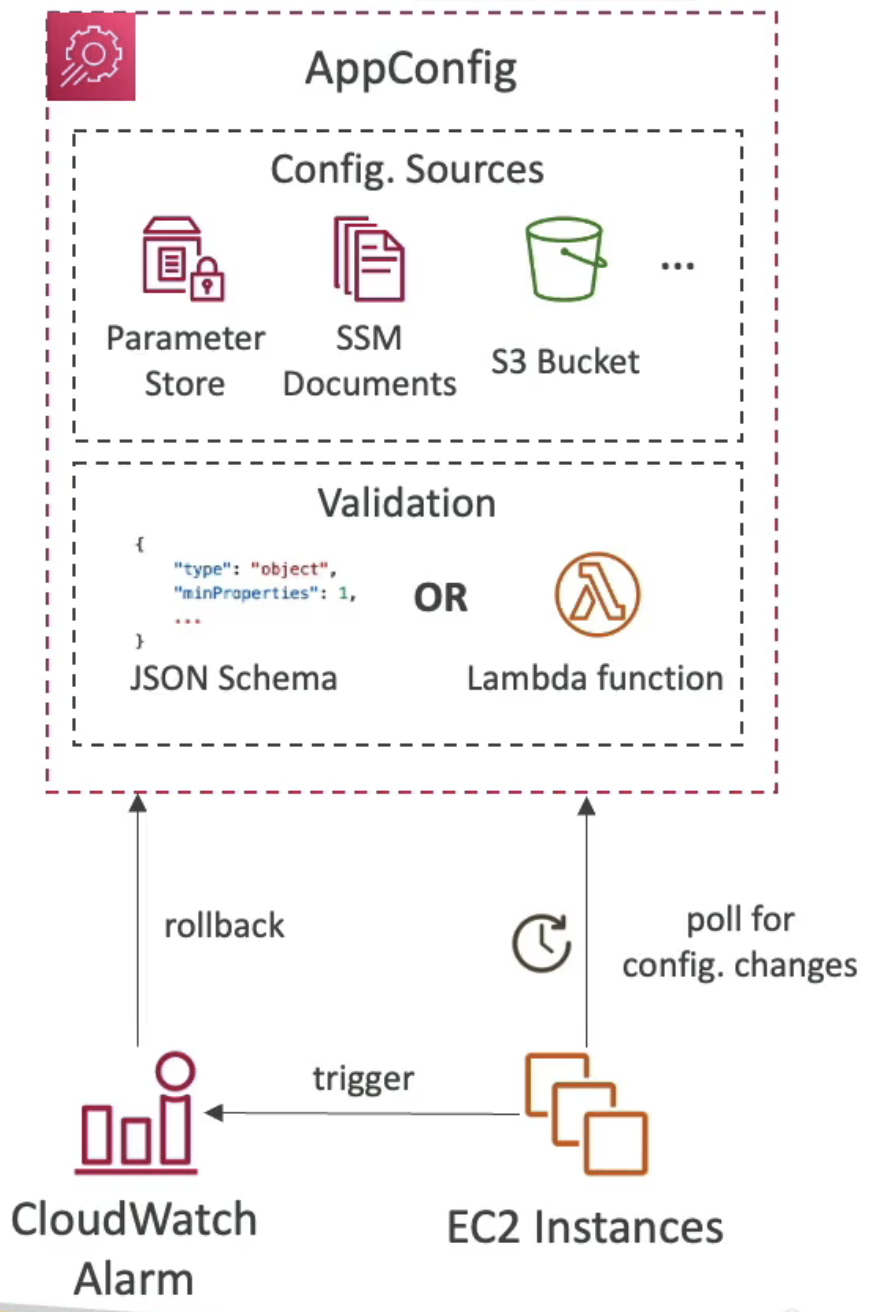
AWS AppConfig
어플리케이션을 구성하기 위해 흔히 사용하는 방법 중 하나는 "앱 구성 정보를 앱과 함께 배포"하는 것이다.
하지만 구성 데이터를 앱 외부에 두고 싶다면 어떻게 해야 할까?
이럴 때 AppConfig를 사용한다. 이를 사용하면 앱을 구성 및 검증하고 구성 데이터를 동적으로 배포할 수 있다.
어플리케이션을 다시 실행하지 않아도 모든 것이 동적으로 반영된다.
Feature flag
- 어플리케이션을 배포하고 AppConfig에서 해당 기능만 꺼두면 된다.
그런 다음 어플리케이션 배포가 완료되고, 테스트 준비가 끝나면 AppConfig에서 기능 플래그 설정을 바꾸어 주면 된다. - 차단할 IP 목록이나 허용할 IP 목록을 AppConfig에서 변경해 실시간으로 반영하는 것도 가능하다.
CloudWatch Evidently
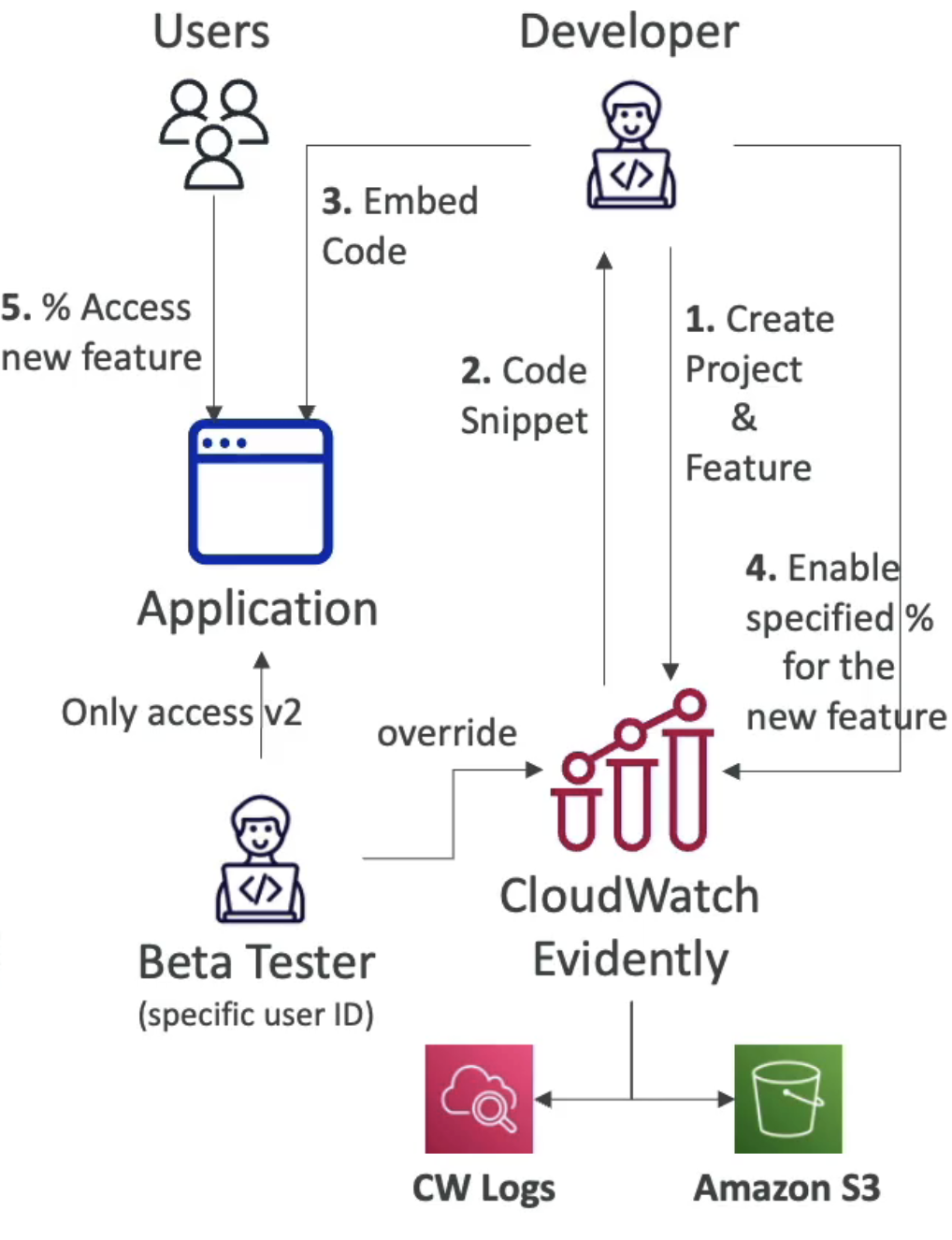
앱의 새로운 기능을 테스트할 수 있게 해주는 CloudWatch의 기능이다.
사용자의 일부분에게만 그 기능을 제공하는 기능이다.
CloudWatch Evidently로 할 수 있는 두 가지 활용 사례는 다음과 같다.
1. Launches
- 일부 사용자들에게 기능을 활성화/비활성화할 수 있다.
2. Experiments
- 같은 기능에 대한 다수의 버전들을 비교한다.
'AWS' 카테고리의 다른 글
| Section 30. AWS 보안 및 암호화: KMS, 암호화 SDK, SSM 파라미터 스토어, IAM 및 STS (1) | 2024.12.26 |
|---|---|
| Section 29. 고급 자격 증명 (1) | 2024.12.11 |
| Section 28. AWS Step Functions 및 AppSync (0) | 2024.12.10 |
| Section 27. Cognito: Cognito 사용자 풀, Cognito 자격 증명 풀 및 Cognito Sync (0) | 2024.12.05 |
| Section 26. Cloud Development Kit(CDK) (1) | 2024.12.04 |



