

Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 자격증
- jpa
- backenddeveloper
- spring
- java
- Spring Boot
- CodeCommit
- aws
- nosql
- 자바
- goorm x kakao
- 스터디
- goorm
- 기본형
- Redis
- serverless
- backend
- data
- Docker
- MSA
- jvm
- 오블완
- 개발자
- mapping
- Cache
- bootcamp
- s3
- orm
- QueryDSL
- 티스토리챌린지
Archives
- Today
- Total
gony-dev 님의 블로그
[Apache Kafka] 카프카란? 본문
카프카는 대규모 데이터 스트리밍을 처리하기 위해 설계된 오픈 소스 분산 메시징 플랫폼이다.
주로 실시간 데이터 처리와 이벤트 중심 아키텍쳐를 지원하는 데 사용된다.
Pub-Sub 모델의 메시지 큐 형태로 동작하며 분산환경에 특화되어 있다!
📌 카프카를 사용하는 이유?
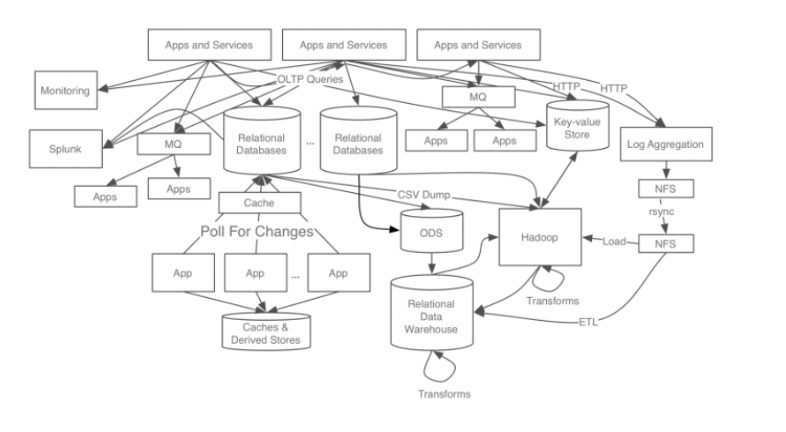
- 기존의 시스템은 데이터 시스템의 복잡도가 높아지면서 다음과 같이 얽혀있는 형태가 되어있었다.
- 이러한 시스템은 다음과 같은 문제점들을 발행한다.
- 시스템 복잡도 증가
- 데이터 파이프라인 관리의 어려움
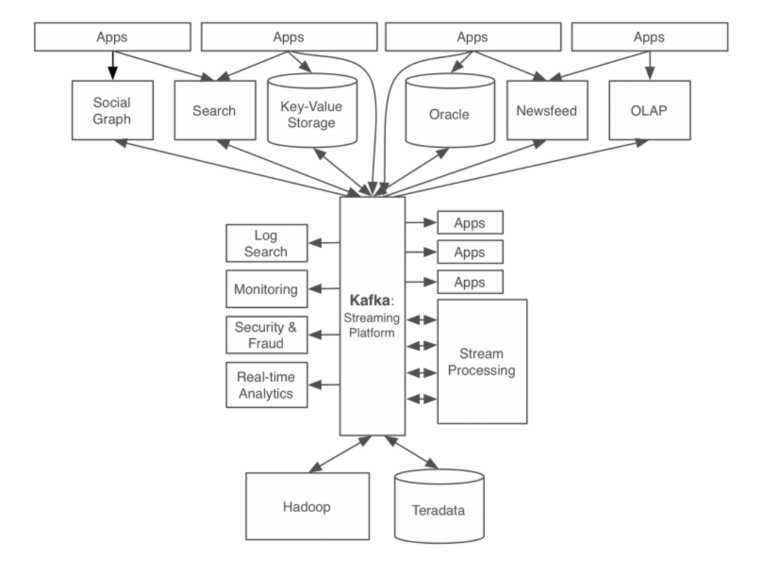
- 그리고 카프카를 적용한 상태의 데이터 처리 시스템은 다음과 같이 변하게 된다.
📌 특징
- 분산 시스템 | kafka는 여러 노드에 데이터를 분산 저장하고 처리할 수 있어서 높은 확장성과 가용성을 가진다.
- 실시간 데이터 처리 | 초당 수백만 건의 메시지까지 처리할 수 있는 높은 처리량을 갖는다.
- Publish-Subscription 모델 | 생산자와 소비자가 주제를 통해 데이터를 송신 및 수신한다.
📌 구성 요소 및 동작 방식
카프카에 담겨있는 요소들은 다음과 같다.
- Producer | 데이터를 카프카의 특정 Topic으로 전송하는 역할이다.
- Consumer | Topic에서 데이터를 받아 읽는 어플리케이션이다.
- Broker | Producer와 Consumer 사이의 중개인 역할로 데이터를 저장하고 관리하는 kafka 서버이다.
- Topic | 데이터는 논리적으로 구분하는 단위이다. Producer는 Topic에 메시지를 쓰고, Consumer는 Topic에서 메시지를 읽는다.
- Partition | Topic은 여러 파티션으로 구성되어 있으며, 이를 통해 병렬 처리를 할 수 있다.
- Zookeeper | 카프카 클러스터의 메타데이터를 관리한다.(kafka 3.x 버전부터는 zookeeper에 의존하지 않도록 하는 방안을 계속해서 구현하고 있다.)
요소들을 토대로 카프카의 동작 방식을 구현해 보면 다음과 같이 구현된다.
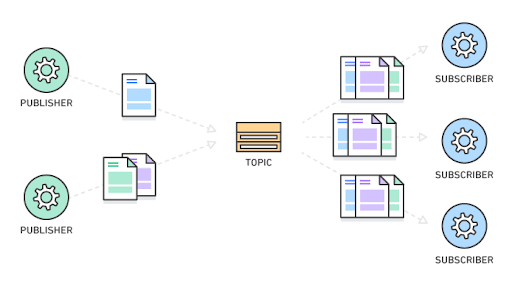
- 일반적인 end-to-end 통신같이 각 개체가 직접적으로 연결되어 있는 형태가 아닌,
Pub/Sub 형태의 모델로 구성되어 있는 비동기 메시징 전송 방식을 채택하고 있다.- 비동기 작업은 특정 작업을 처리하는 동안 결과의 완료 여부에 상관없이 다른 작업을 동시에 처리할 수 있는 방식을 의미한다.
- Publisher는 수신자가 정해져 있지 않은 메시지를 발송한다.
그리고 해당 메시지를 Subscribe한 수신자만 해당 메시지를 받을 수 있다. - 이러한 구조는 높은 확장성을 확보할 수 있다.
- 해당 구조는 Kafka 뿐만 아니라 Redis나 AWS SQS 같은 서비스도 따르고 있다.
'Kafka' 카테고리의 다른 글
| [Apache Kafka] Spring boot 3.x.x과 Kafka 연동하기 (3) | 2024.11.18 |
|---|
'Kafka' Related Articles
more
