
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 오블완
- backenddeveloper
- Docker
- orm
- nosql
- java
- QueryDSL
- 티스토리챌린지
- CodeCommit
- bootcamp
- 스터디
- goorm
- 자격증
- aws
- spring
- backend
- s3
- 자바
- mapping
- 개발자
- Spring Boot
- Redis
- goorm x kakao
- 기본형
- MSA
- jpa
- Cache
- jvm
- serverless
- data
Archives
- Today
- Total
gony-dev 님의 블로그
Section 22. AWS Serverless: DynamoDB - 1 본문
DynamoDB란?
1. NoSQL databases
- Not Only SQL 또는 Non SQL 데이터베이스를 의미한다.
- 수평성 확장성을 가지며 MongoDB나 DynamoDB를 포함한다.
- 조인 쿼리를 지원하지 않으며 필요한 모든 데이터는 한 줄로 표시되어야 한다.
- 수평 확장성을 가지기에 더 많은 인스턴스를 추가해서 스케일링할 수 있다.
DynamoDB
- 완전 관리되고 고가용성의 NoSQL 데이터베이스이며, RDS와는 다르다.
- 대규모 워크로드로 확장되고 완벽히 분산된다.
- 초당 수백만 개의 요청과 수조 개의 행, 수백 테라바이의 스토리지로 확장할 수 있다.
- 검색 시 지연 시간이 낮고 IAM과 통합되어 있다.
1. Basic
- DynamoDB는 테이블들로 이루어져 있으며, 각각의 테이블은 기본 키를 갖는다.
- 각 테이블은 행을 무한대로 가질 수 있고, 각 행은 속성들을 가진다.
- 항목의 최대 사이즈는 400KB이다.
- 지원되는 데이터 유형들
- 스칼라 타입 | String, Number, Binary etc.
- 문서 타입 | List, Map
- 집합(Set) 타입 | String Set, Number Set, Binary Set etc.
2. Primary Keys
- 기본 키에는 두 개의 옵션이 있다.
Option 1: Partition Key(HASH)
- 파티션 키는 각 행당 고유한 값을 가져야만 한다.
- 데이터가 고루 분산되어야 하기에 다양해야 한다.

Option 2: Partition Key + Sort Key (HASH + RANGE)
- 이 혼합된 값도 역시 고유한 값을 가져야하며, 데이터는 기본 키에 의해 그룹화 된다.

DynamoDB - Read/Write Capacity Modes
- 테이블의 용량을 제어하는 방법으로 사전에 읽기/쓰기 처리량을 지정한다.
- 모드는 2가지가 존재한다.
- Provisioned Mode(Default)
- 초당 읽기/쓰기를 지정
- 사전에 용량을 계획해야한다.
- 무엇이든 간에 프로비저닝되는 용량의 유닛에 따라 비용을 지불한다.
- On-Demand Mode
- 워크로드에 기반하여 읽기/쓰기를 자동으로 스케일 업/다운한다.
- 용량을 사전에 계획할 필요가 없다.(=프로비저닝 할 필요가 없음)
- 프로비저닝 모드보다 훨씬 비싸다..
- Provisioned Mode(Default)
1. R/W Capacity Modes - Provisioned
- 해당 모드는 테이블이 읽기/쓰기 용량 단위에 대해 프로비저닝 되어야 한다.
- RCU - 읽기 처리량, WCU - 쓰기 처리량을 의미한다.
- 수요를 만족시키기 위해 처리량을 오토 스케일링하도록 설정해주는 옵션이 있다.
- 만일 프로비저닝한 것보다 더 많이 소비한다면, 버스트 용량을 일시적으로 사용할 수 있기에 괜찮다.
- 하지만 버스트 용량 마저도 다 사용하게 된다면, "프로비저닝 처리량 초과 예외"라는 예외가 발생한다.
- 이러한 예외가 발생한다면 작업을 다시 시도하게 되며, 지수 백오프를 통해 시도한다.
2. Write Capacity Units (WCU)
- 하나의 WCU는 크기가 1KB까지인 아이템에 대해 초당 한 개의 쓰기를 의미한다.
- 만일 아이템이 1KB보다 크다면, 더 많은 WCU를 소비하게 된다.
- ex. 초당 10개의 아이템을 쓰고, 아이템 사이즈가 4.5KB라면 10*5KB=50이 된다.
3. Strongly Consistent Read vs. Eventually Consistent Read
- Eventually Consistent Read(default)
- 쓰기 후에 읽는다면, 복제 때문에 오래된 데이터를 얻을 수 있다.(=복제가 일어나서가 아닌 너무 빨라 복제가 일어나지 않아서!)
- Strongly Consistent Read
- 쓰기 이후에 데이터를 읽는다면 막 쓰인 데이터를 올바르게 읽을 수 있다.
- API 호출에서 "ConsistentRead"라는 매개변수를 참으로 해야한다.
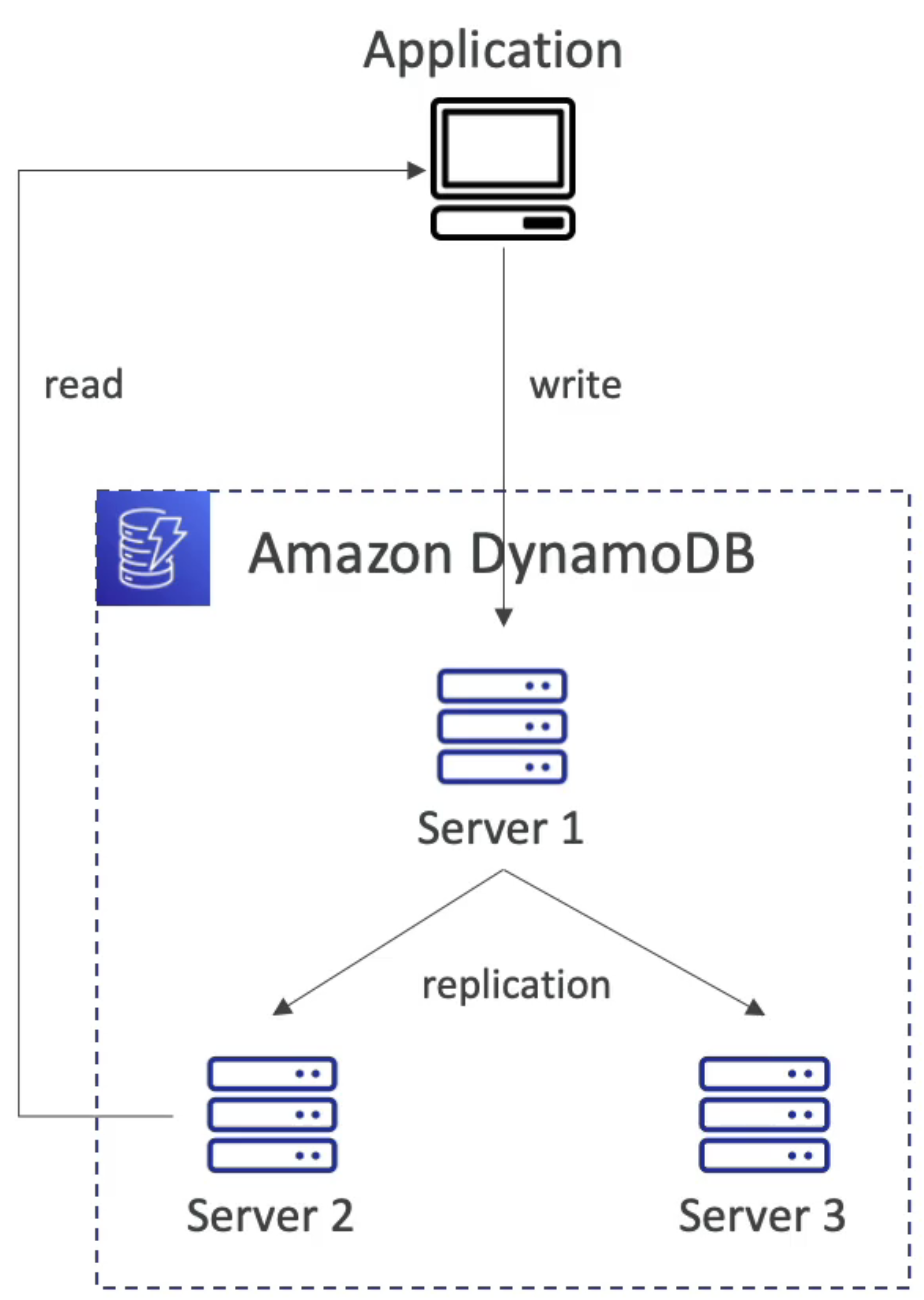
4. Read Capacity Units (RCU)
- 하나의 RCU는 크기가 최대 4KB인 아이템에 대해 초당 하나의 강력한 일관적 읽기 또는 초당 2개의 최종적 일관적 읽기를 나타낸다
- 만일 아이템이 4KB보다 크면, 더 많은 RCU가 소비된다.
- ex. 초당 16개의 최종적 일관적 읽기가 있고, 아이템의 크기가 12KB라면 (16/2) * (12/4) = 24 RCU가 된다.
5. Partitions Internal
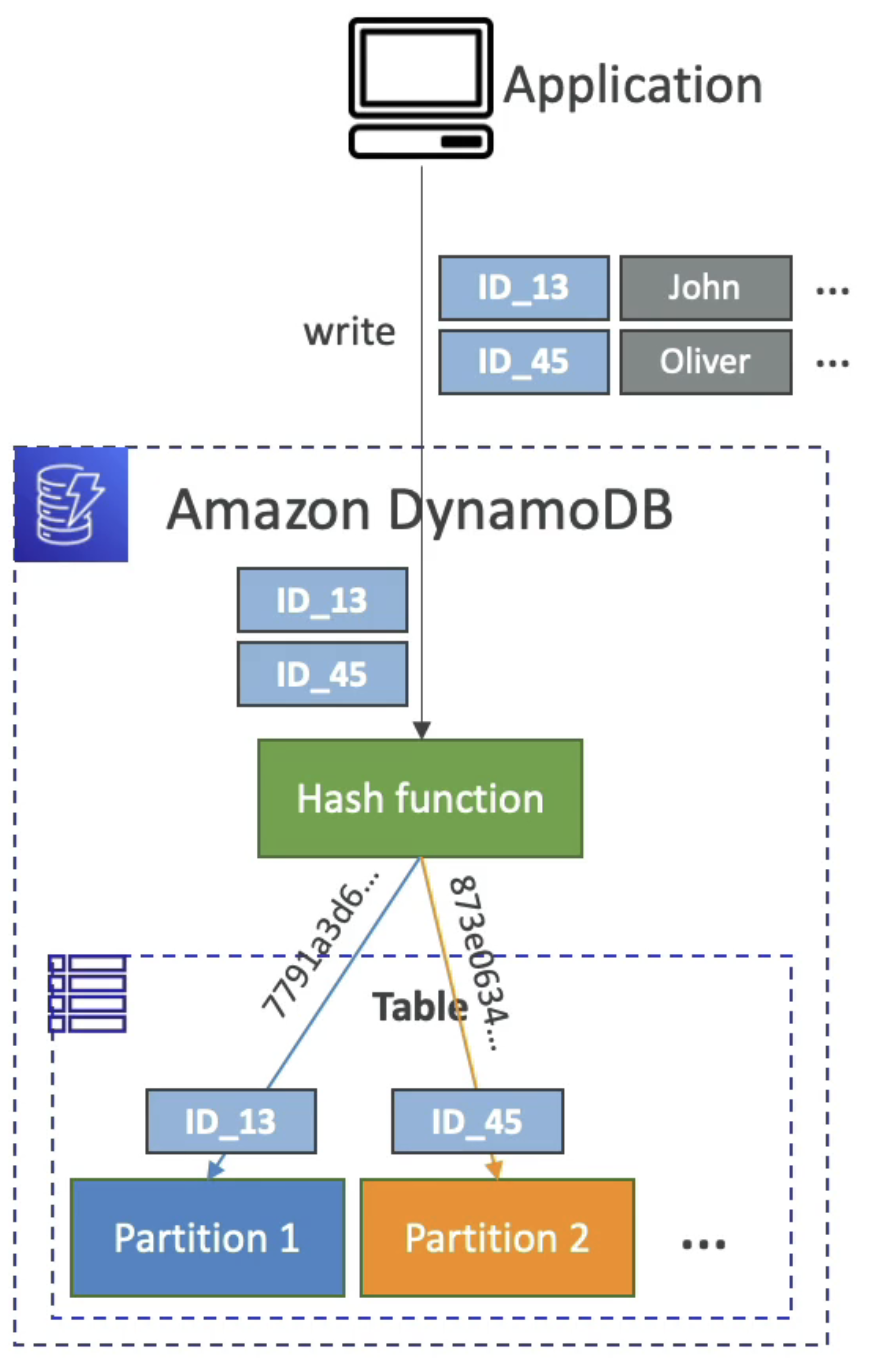
- 데이터는 분할되어 저장되어야 한다.
- 기본 키는 어떤 분할된 장소로 가야할지 알고 있는 해시 알고리즘을 통과하여 파티션 장소에 도달한다.
- WCU와 RCU는 고르게 분할되어 퍼져야만 한다!
- 분할 테이블들의 개수를 구하는 공식은 다음과 같다.

6. Throttling
- 파티션 수준에서 프로비저닝된 RCU와 WCU를 초과한다면, "프로비저닝 처리량 초과 예외"가 발생한다.
- 이유는 다음과 같이 여러 가지가 있을 수 있다.
- Hot Keys | 하나의 기본키가 너무 많이 읽혔기 때문
- Hot Paritions
- Ver large items | 아이템이 너무 크면, 그만큼 RCU와 WCU도 많이 쓰이게 된다.
- 해결방안은 다음과 같다.
- 예외 사항을 직면했을 때 지수 백오프 방식을 사용한다.
- 파티션 키를 가능한 최대한 많이 분산한다.
- RCU에 문제가 발생했다면, DynamoDB Accelator(DAX)를 살펴보아야 한다.
7. R/W Capacity Modes - On-Demand
- 어떤 읽기와 쓰기든 자동으로 승인하여 워크로드에 따라 스케일 업/다운을 시도한다.
- 용량 계획을 할 필요가 없다.
- 그렇기에 비싸다.
- RRU - 읽기 요청 유닛, WRU - 쓰기 요청 유닛
- Provisioned와 연산은 같지만, 성공적으로 처리된 요청만 있기에 요청을 기반으로 계산한다.
- 알려지지 않은 워크로드나, 예측 불허한 어플리케이션 트래픽에서 사용하는 것을 추천한다.
DynamoDB Basic API
1. Writing Data
데이터 작성 시 몇 가지 선택할 수 있는 사항들이 있다.
- PutItem
- 기본 키가 같은 새 항목을 만들거나 완전히 교체한다.
- 쓰기 용량 단위(WCU)를 소모한다.
- UpdateItem
- 기존 항목의 속성을 편집하거나, 항목이 존재하지 않을 경우에는 새 항목을 추가한다.
- PutItem과 달리 모든 속성을 편집하진 않는다.
- 원자성 카운터와 함께 사용할 수 있다.
- Conditional Writes
- 조건이 총족되었다면 쓰기/업데이트/삭제를 받아들이고, 그렇지 않으면 오류를 반환한다.
- 항목에 대한 동시성 접근을 도와준다.
2. Reading Data
- GetItem
- 기본 키에 기반하여 읽기를 수행한다.
- 기본 키는 Hash나 Hash+Range가 될 수 있다.
- 최종적 일관된 읽기와 강력한 일관된 읽기 모드를 사용할 수 있다.
- 강력한 일관된 읽기 모드의 경우, RCU가 더 들고 지연 시간이 늘어날 수 있다.
- API에 "ProjectionExpression"을 지정할 수도 있는데, 이것은 오로지 확실한 속성 몇 가지만 받을 수 있다.
2-1. Reading Data(Query)
- 쿼리는 아이템을 반환하는데 여러 요소에 기반하여 반환한다.
- KeyConditionExpression
- KeyConditionExpression은 파티션 키에 따라 항목을 반환한다.
- 정렬 키는 선택적으로 선택할 수 있고, 미만, 초과 등이 가능하다.
- FilterExpression
- 쿼리 작업이 완료된 후, 필터링을 추가한다.
- 비식별자 속성에만 사용된다.(=HASH나 RANGE 속성을 허용하지 않는다.)
- KeyConditionExpression
- 쿼리가 반환하는 것들
- limit 쿼리 매개변수에 따라 가져올 항목 수가 제한
- 또는 최대 용량인 1MB에 도달할 때 반환된다.
- 시간에 따라 데이터를 더 가져오고 싶다면 결과를 페이지네이션하면 된다.
2-2. Reading Data(Scan)
쿼리가 특정한 파티션 키, 정렬 키라면 항목 Scan은 테이블 전체를 읽는다.
- 원하면 데이터를 필터링 할 수 있으나 그것은 클라이언트에서만 가능하다.
- Scan은 전체 테이블을 내보내고 각 Scan은 최대 1MB의 데이터를 반환하며 계속 읽고 싶다면 페이지네이션 기술을 사용해야 한다.
- 전체를 읽기에 RCU를 많이 소모하며 정상적인 작업을 이어나가고 싶다면 Limit문을 Scan에 적용하거나, 결과 크기를 줄이고 중지해야 한다.
3. Deleting Data
- DeleteItem
- 개별 항목을 삭제한다.
- 또한 조건부 삭제도 가능하다.(0이 될때 삭제하는 조건)
- DeleteTable
- 전체 테이블과 모든 항목을 삭제한다.
- DeleteItem을 사용하여 모든 항목을 삭제하는 것보다 훨씬 빠르다.
4. Batch Operations
Batch Operations는 API 호출 수를 감소시켜 지연시간을 절약할 수 있게 한다.
Operations은 더 나은 효율성으로 병렬 작업을 수행한다.
일괄 작업이기에 일부분이 실패할 수가 있는데 그렇게 되면 실패한 항목만 다시 시도할 수 있다!
- BatchWriteItem
- 25번까지 PutItem과 한 번의 DeleteItem을 수행한다.
- 최대 16MB의 데이터를 기록할 수 있다.
- 항목을 업데이트할 수는 없다.
- 항목을 작성할 수 없을 때는 UnprocessedItems가 반환되며 재시도가 가능하다.
- 지수 백오프 전략이나 WCU를 추가하여 이를 해결 할 수 있다.
- BatchGetItem
- 하나 이상의 테이블로부터 항목들을 반환한다.
- 100개까지 가능하여 최대 16MB의 데이터까지 가능하다.
- 지연 시간을 최소화하기 위해 모든 항목을 병렬로 가져온다.
- 일부 항목이 누락될 경우 용량이 부족해서 읽기 작업에 실패하여 UnprocessedKeys가 반환된다. 이때 위와 같은 방법으로 해결할 수 있다!
5. PartiQL
- SQL | DynamoDB로 호환 가능한 쿼리 언어를 다룰 수 있다.
- select, update, insert, delete의 명령어를 허용한다.
- 다수의 DynamoDB 테이블들에 걸쳐 쿼리를 수행하며, PartiQL 쿼리들이 실행되는 곳들은 다음과 같다.
- AWS Management Console
- NoSQL Workbench Console
- DynamoDB APIs
- AWS CLI
DynamoDB - conditional Writes
조건부 쓰기
쓰기 항목들에 대해서는 수정해야 할 항목을 결정할 조건 표현식을 지정할 수 있다.
예시로는 attribute_exists, attribute_not_exists, attribute_type, contains, begins_with, ProductCategory IN 등등이 있다.
중요한 점은 필터 표현식은 조건부 표현식이 쓰기 작업을 하는 동안 읽기 쿼리의 결과를 필터링한다는 것이다.
DynamoDB - Index
1. Local Secondary Index(LSI)
- LSI는 테이블에 대체 정렬 키를 의미한다.
- 이 정렬 키는 하나의 스칼라 속성으로 구성되어 테이블당 최대 5개의 키를 얻을 수 있다!
- LSI는 반드시 테이블 생산 시점에 정의되어야 하며 테이블 생성 후에는 생성할 수 없다.
- Attribute Projections | LSI에서는 메인 테이블의 특정 또는 모든 속성을 포함할 수 있다.(All, Only Keys, Include 중 선택 가능)

2. Glabal Secondary Index(GSI)
- 메인 테이블에서의 대체 기본 키를 의미한다. 그래서 다른 해시 키와 파티션 키를 갖거나 기본 테이블에서의 다른 해시 키와 정렬 키도 가질 수 있다.
- 테이블 내에 키 속성이 아닌 항목의 쿼리 속도를 높이는데 유용하다.
- Attribute Projections | 메인 테이블의 특정 또는 모든 속성을 지정할 수 있다.
- 이 GSI에 관해서 반드시 RCU와 WCU를 프로비저닝 해야만 한다!
- GSI는 테이블 생성 후에도 추가나 수정이 가능하다!

3. Indexes and Throttling
- GSI의 경우,
- 쓰기가 GSI에서 스로틀되면, 메인 테이블도 스로틀 된다!
- 메인테이블에서 WCU에 아무런 문제가 없어도, GSI에 제한이 있으면 메인 테이블도 제한이 된다..
- 따라서, GSI와 파티션 키를 신중하게 선택해야 하며 WCU 용량도 신중히 할당해야 한다.
- LSI의 경우,
- 메인 테이블에서 WCU와 RCU를 둘다 사용한다.
- 스로틀을 고려할 필요는 없다.
DynamoDB - PartiQL
- PartiQL은 DynamoDB 테이블을 조작하는 SQL과 비슷한 구문을 사용한다.
- 지원하는 상태로는 SELECT, UPDATE, INSERT, DELETE가 있다.(기존 SQL과 비슷)

'AWS' 카테고리의 다른 글
| Section 23. AWS Serverless: API Gateway (0) | 2024.11.15 |
|---|---|
| Section 22. AWS Serverless: DynamoDB - 2 (1) | 2024.11.08 |
| Section 21. AWS 서버리스: Lambda - 2 (2) | 2024.11.05 |
| Section 21. AWS 서버리스: Lambda - 1 (2) | 2024.11.03 |
| Section 20. AWS 모니터링 및 감사: CloudWatch, X-Ray 및 CloudTrail - 2 (1) | 2024.10.24 |
'AWS' Related Articles
more



