Kinesis는 스트리밍되는 데이터를 실기간으로 수집, 처리 및 분석하도록 도와준다. 어플리케이션 로그, 지표, 웹사이트 클릭스트림, IoT 원격 데이터 등 실시간 데이터 어느 것이든 될 수 있다. 그 중 Kinesis Data Streams는 데이터 스트림을 입력, 처리 및 저장할 수 있고, Kinesis Data Firehose는 내부나 외부의 데이터 스토어로 데이터를 로드한다. Kinesis Data Analytics는 SQL이나 Apache Flink를 통해 데이터 스트림을 분석한다.
Kinesis Data Streams
Kinesis Data Streams는 1개 이상의 샤드로 이루어져 있으며, 이 샤드는 사전에 프로비저닝되어 있어야 한다.
모든 샤드에 걸쳐 데이터는 분산되고, 샤드가 수집 및 소비율에 맞춰 스트림 용량을 정의한다.
Kinesis Data Streams로 데이터를 보내는 생산자도 존재한다.
생산자는 Kinesis Data Streams 레코드를 생성한다.
레코드는 두 가지로 구성되며, 파티션 키와 최대 1MB를 가지는 데이터 블롭이다.
데이터를 보낼 때는 샤드당 1MB/sec이나 1,000MPS로 데이터가 전송된다.
생산자로부터 받은 Kinesis Data Steams 내의 데이터는 소비자로 전송이 된다.
소비자가 레코드는 수신할 때는 파티션 키와 함께 레코드가 샤드의 위치에 있었던 위치를 나타내는 시퀀스 번호, 데이터 블롭으로 구성된 레코드는 받는다.
이때의 처리량을 공유할 때는 전체 소비자가 샤드당 2MB/sec을 받거나 팬아웃을 활성화한다면 2MB/sec를 받는다.
Kinesis Data Streams 특징
1~365일의 보유 기간 설정 가능
데이터를 재처리하거나 반복 가능
Kinesis에 삽입된 데이터는 삭제 불가
Kinesis Data Streams에 데이터를 보내면 파티션 키가 추가되는데, 같은 파티션 키를 공유하는 메시지는 동일한 샤드로 이동하여 키 기반 순서를 제공한다.
소비자는 직접 KCL이나 SDK를 작성할 수 있으며, AWS Lambda, Kinesis Data Firehose or Analytics의 관리형 소비자일 수 있다.
Kinesis Data Streams - Capacity Modes
Provisioned mode
몇 개의 샤드 프로비저닝을 선택한 후, 수동이나 API를 사용해 확장한다.
각 샤드는 1MB/sec이나 1000RPS를 보인다.
출력 처리량은 2MB/s이다.
On-demand mode
용량을 프로비저닝하거나 관리할 필요가 없다. 시간 흐름에 따라 조정됨
4MB/s or 4000 RPS의 기본 용량 프로비저닝이 있고, 지난 30일에 한해 ASG가 활성화된다.
Kinesis Data Streams Security
Kinesis Producer
kinesis에서 데이터를 가져오는 법을 알아보자.
생산자는 데이터를 데이터 스트림에 보낸다.
데이터 레코드는 일련의 번호와 파티션 키, 데이터 블롭으로 이루어져 있다.
생산자는 어떤 SDK도 가능하며, KPL를 사용할 수 있다. 이때 KPL은 배치 처리, 압축, 재시도 등의 기능을 수행할 수 있다.
쓰기 처리량은 샤드당 1MB/sec or 1000 RPS를 사용한다.
디바이스당 파티션 키를 만들어 해시 함수에 전송한다.
만일 분산된 파티션 키를 잘 이용하지 않으면 프로비저닝처리량 초과가 발생한다.
이를 해결할 방법은 다음과 같다.
매우 잘 분산된 파티션 키를 사용
기하급수적인 백오프를 통해 재시도를 구현해서 예외 상황을 재시도해야 한다.
샤드를 스케일링해야 한다. 샤드를 분할하여 처리량을 증가시키는 방법이다.
Kinesis Data Streams Consumers
소비자는 스트림으로부터 레코드를 가져오고 저리한다.
소비자는 람다, Kinesis Data Analytics, Kinesis Data Firehose, SDK, KCL를 이용한 사용자 정의 소비자가 될 수 있다.
사용자 정의 소비자는 두 가지 모델이 있다. 이를 알아보자.
1. Shared Fan-out consumer
Pull Model로 모든 소비자에 걸쳐 샤드당 2MB/sec의 처리량을 제공한다.
즉, 3개의 소비자 어플리케이션이 있으면 소비자 하나 당 초당 666KB를 제공받는다.
적은 수의 소비자 어플리케이션이 있을 때 유리하며, 최대 5개의 GetRecords API 호출을 가질 수 있다.
200ms까지 지연 시간을 늦출 수 있다.
10 MB or 10000 records까지 반환할 수 있다.
2. Enhanced Fan-out Consumer
Push Model로 샤드당 소비자에게 2MB/sec의 처리량을 제공한다.
즉, 3개의 소비자 어플리케이션이 있으면 각각 2MB/sec를 제공하므로 샤드는 6MB/sec를 갖는다.
다수의 어플리케이션에 유용하며 70ms까지 지연 시간을 늦출 수 있다.
HTTP/2 방식으로 소비자에게 데이터를 푸시한다.
데이터 스트림 당 5개의 소비자 어플리케이션이라는 제약이 있지만 티켓을 올려 올릴 수 있다.
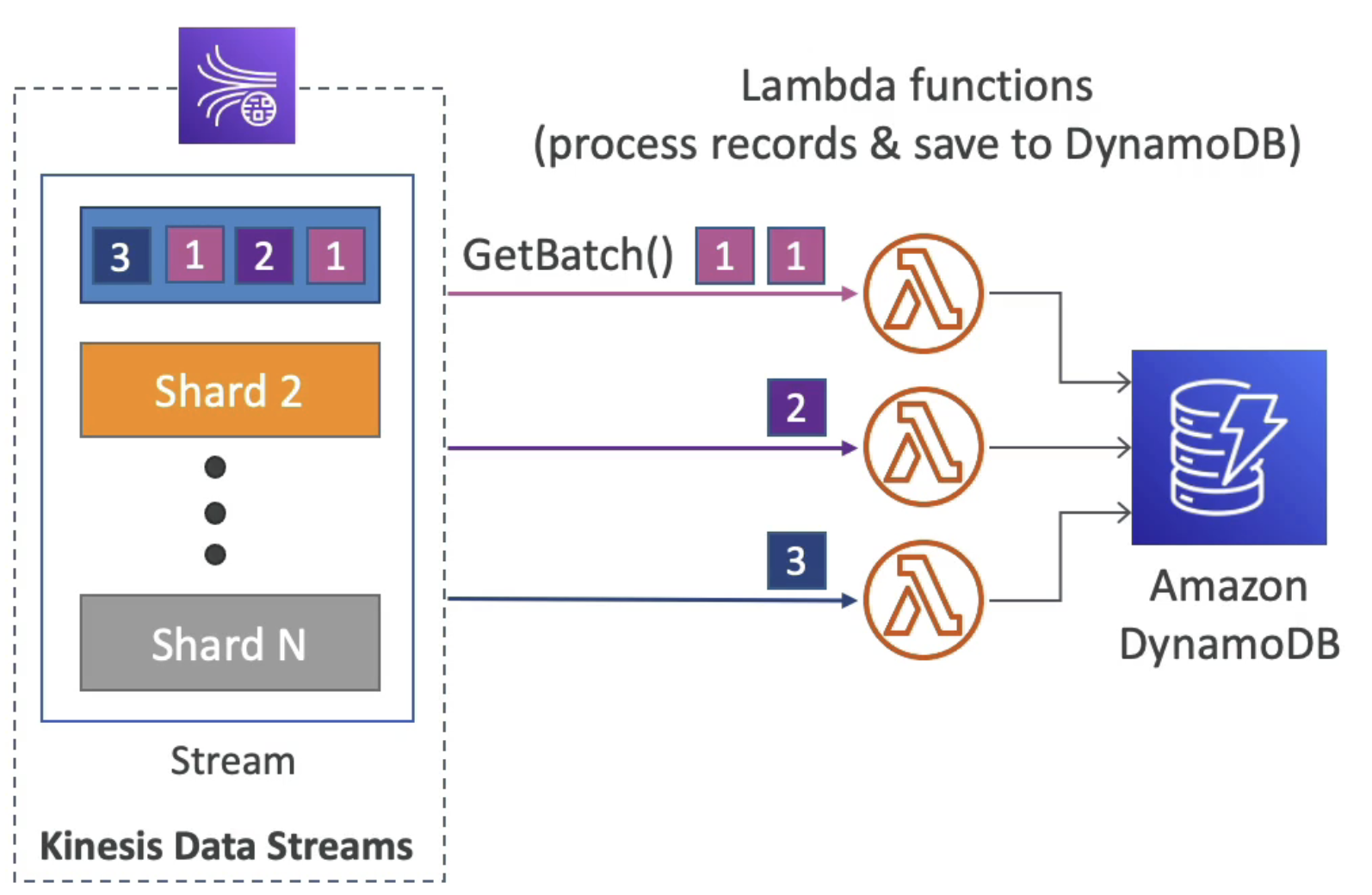
마지막으로 AWS 람다에 대한 소비자를 알아보자.
람다는 위에 설명한 Classic과 Enhanced 모델 둘 다 사용이 가능하며, 배치에 따라 레코드를 읽는다.
배치 사이즈와 window를 정할 수 있다.
만일 에러가 발생하면, 람다는 성공이나 데이터가 만료될 때까지 재시도한다.
동시에 샤드당 10 배치까지 처리할 수 있다.
Kinesis Client Library(KCL)
시나리오 문제에 주의!
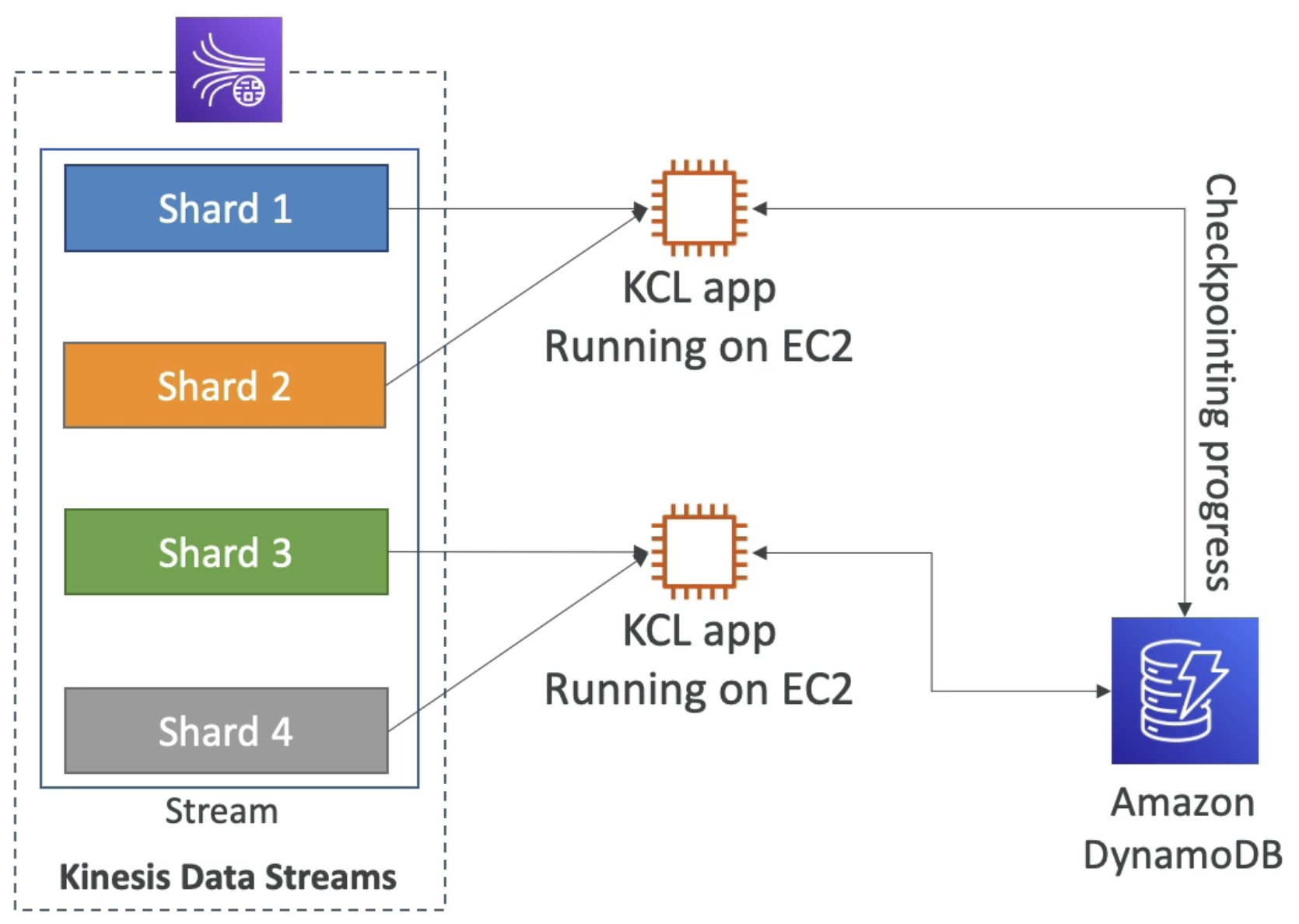
자바 라이브러리는 Kinesis Data Stream에서 읽기 워크로드는 공유하는 분산 어플리케이션의 레코드를 읽을 때 도움을 준다.
각 샤드는 KCL 인스턴스에서만 읽히며, 이 말은 4개의 샤드가 있을 때 최대 4개의 KCL 인스턴스가 있다는 의미이다. Kinesis Client Library는 Kinesis Data Streams로부터 읽는데, 얼마나 읽었는지에 대한 과정을 DynamoDB에 체크포인트로 남긴다. 이때, IAM 액세스가 필요하다.
레코드는 샤드레벨에 따라 순서대로 정렬된다. KCL도 버전이 있는데, 1.x 버전은 공유된 소비자만을 지원하며 2.x 버전은 공유된 소비자와 향상된 팬아웃 소비자 모드를 지원한다.
하나의 어플리케이션이 정지되어도 저장된 체크포인트를 다른 어플리케이션에서 재가동위의 사진에서 스케일업한 4shards
Kinesis Data Firehose
생산자로부터 데이터를 가져올 수 있는 서비스 Kineses Data Streams에서 본 모든 것이 생산자가 될 수 있다.
특징
완전 관리형 서비스로, 관리가 필요 없으며 자동 스케일링에 서비리스이므로 관리해야 할 서버가 없다.
위의 사진처럼 redshift, Amazon S3, OpenSearch와 같은 AWS 수신처로 데이터를 보낼 수 있다.
Firehose를 통해 거쳐가는 데이터에 대해서만 지불을 하면 되므로 가성비가 좋다.
실기간으로 작동되는데 이유는 우리가 Firehose에서 수신처까지 일괄적으로 데이터를 작성하기 때문이다.
따라서 버퍼 간격이 있으며 0초를 하거나 비활성화를 하면 더 높은 숫자로 설정할 수 있다.
최대 900초까지 가능.
실패 또는 모든 데이터를 S3 버킷에 백업할 수 있다.
Kinesis Data Streams vs. Firehose
1. Kinesis Data Streams
대규모 데이터를 수집하는데 사용되는 스트리밍 서비스.
생산자와 소비자를 위한 사용자 지정 코드를 직접 작성.
실시간.
규모와 처리량을 높이기 위해 샤드 분할과 샤드 병합을 수행한다.
데이터 저장 기간은 1~365일까지 가능하다.
2. Kinesis Data Firehose
수집 서비스로 다양한 곳으로 스트리밍할 수 있다.
완벽하게 관리되며 서비리스 서비스이다.
자동 스케일링 가능.
데이터 스토리지가 존재하지 않는다.
Kinesis Data Analytics
1. SQL Application
SQL을 사용하여 Kinesis Data Streams & Firehose를 실시간 분석한다.
Amazon S3로 데이터를 보충할 수 있다.
완전 관리형이고, 서버리스이다.
자동 스케일링이 가능하다.
출력은 Kinesis Data Streams이나 Kinesis Data Firehose를 사용한다.
사용 예시로는 시분할 분석이나 실시간 대시보드, 측정이 있다.
2. Apache Flink
Flink를 사용해서 스트리밍 데이터를 분석한다.
AWS에서 관리되는 클러스터의 Apache Flink application을 실행하면 다음과 같다.
프로비저닝된 자원 계산, 병렬 계산 및 오토 스케일링
체크포인트나 스냅샷으로 구현되는 백업이 가능하다.
Apache Flink 프로그래밍 기능 사용 가능
Kinesis Data Firehose는 Flink로부터 데이터를 읽을 수 없다.(원한다면 SQL를 이용해야 한다.)
Ordering data into Kinesis or SQS
1. Kinesis
도로에 여러 대의 트럭이 있고 각 트럭에는 트럭 ID가 있다. 100까지 도로에 있으며 GPS 위치를 주기적으로 AWS에 보낸다고 가정하자.
그런 다음 각 트럭의 순서대로 데이터를 소비하여 트럭의 이동을 정확히 추적하고 경로를 순서대로 확인하려고 한다.
이때 Kinesis를 어떻게 활용할 수 있을까?
정답은 트럭 ID의 값에 대한 파티션 키를 사용하는 것이다. 이유는 같은 키를 사용할 경우에는 항상 같은 샤드로 전달되기 때문이다.
해시된 아이디에 따라 해당 샤드로 이동한다.
2. SQS
SQS는 순서가 없다.
하지만 SQS FIFO의 경우에는 순서가 있다. 만일 SQS FIFO의 그룹 ID를 사용하지 않으면, 모든 메시지는 그들이 보낸 오직 한 명의 소비자에게만 순서대로 보내질 것이다.
많은 소비자를 스케일링하고 싶고, 서로 연관된 메시지를 그룹화 하고 싶다면 그룹 ID를 사용하자!